· Blog · 16 min read
AI Has a Fidelity Problem Nobody Is Measuring
Every major AI lab publishes benchmarks for reasoning, coding, and math. But nobody is measuring whether AI actually gets human expertise right. We built an evaluation framework to find out.

Every major AI lab publishes benchmarks for reasoning, coding, and math. But nobody is measuring whether AI actually gets human expertise right. We built an evaluation framework to find out.
A parent is navigating a child’s autoimmune diagnosis. The questions span immunology, nutrition, and developmental health. No single textbook covers the territory. A patient is managing metabolic syndrome where sleep, stress, and diet interact in ways that depend entirely on their specific situation.
These are not factual lookup problems. There is no single right answer. Reasonable, credentialed experts genuinely disagree with each other about how to approach them, and the disagreement is not a flaw. It is the nature of the domain.
In these areas, people do not need “the answer.” They need a specific expert’s answer. A nutritionist chosen because their methodology fits your values and situation. A physician whose clinical philosophy aligns with how you want to manage your health. The question is never “what is the best nutrition.” It is “what would this expert recommend for me.”
This is what expert opinion means, and it is how humans have always navigated complex decisions. But AI has a structural problem with it. Every frontier model is trained to converge on consensus. Ask a contested question and you get the averaged-out, hedge-everything middle. That is fine for queries with clear factual answers. It is inadequate for the problems where people most need help, precisely because those problems require a point of view, not a summary of all points of view.
If you believe expert opinion matters for complex health decisions, then you care about one thing above all: is the AI system delivering that opinion actually faithful to what the expert knows and believes? Or is it generating a plausible approximation from its training data?
We call this the fidelity problem. The model is fluent but unfaithful. It does not hallucinate in the traditional sense. It does something worse: it produces answers that sound like the expert, pass a surface-level plausibility check, and are wrong in ways that only someone deeply familiar with that expert’s actual body of work would catch. It generates a confident synthesis of adjacent ideas from its training data and attributes them to an expert who never said those things, or who would actively disagree with the framing. One failure is a fidelity gap. The other is misinformation.
The AI industry has developed separate benchmarks for factual faithfulness, persona consistency, and knowledge groundedness. But no existing benchmark combines these dimensions to evaluate how faithfully an AI system represents a specific human expert’s knowledge, voice, and methodology against their own proprietary content. There is no leaderboard. There is no standard.
We built one.
How the Evaluation Works
We tested Onix against ten of the most capable commercial AI models: GPT-5.4, GPT-5.2, GPT-5 Mini, Gemini 3 Flash, Gemini 3 Pro, Gemini 3.1 Pro, Gemini 2.5 Flash, Claude Opus 4.6, Claude Sonnet 4.6, and Claude Haiku 4.5. Eleven players, same questions, head to head.
Each model was asked the same set of questions across seven expert domains in health and wellness. The questions were generated directly from each expert’s actual corpus, designed to probe specific knowledge that only a system genuinely grounded in that expert’s body of work would get right. A good test question is one where a commercial model’s general training produces a plausible-sounding answer that differs from what the expert actually said.
Onix builds a dedicated knowledge system for each expert, grounded only in that expert’s own corpus: their published and unpublished body of work. At answer time, it uses a dedicated knowledge architecture to stay aligned with the expert’s actual methodology and voice, instead of guessing from general web-scale training. Some of these corpora span thousands of documents and decades of work. The commercial models answered from their general training alone, with no access to any of this material, which matches what a real user encounters today when they ask a commercial AI about a specific expert.
We scored 2,080 responses using ELO ratings, the same ranking system used in competitive chess and widely adopted AI benchmarks like Chatbot Arena. Every model starts at 1500. When one model outscores another on the same question, it wins the matchup. Ratings adjust across all head-to-head comparisons, shuffled and averaged over 50 passes for stability. A gap of roughly 280 points means the higher-rated model would win 9 out of 10 matchups. The bigger the gap, the more dominant the advantage.
Every response was scored by an independent AI judge (Claude Sonnet 4.6), selected after a calibration study across 351 test cases where it achieved 94.7% accuracy and 96.4% precision. We also found that other judges showed measurable bias toward their own outputs: GPT-5.2 inflated its own scores by 31.5 percentage points. Judge selection changes outcomes, so we disclose ours.
Key Findings
Expert Fidelity is a composite score measuring three dimensions of how faithfully an AI represents a specific expert: accuracy, persona, and groundedness. We define each in detail below.
- Fidelity: Onix leads on composite Expert Fidelity across all seven domains. The largest advantage is +350 ELO, roughly a 90% expected win rate. The smallest, +132 ELO, still represents consistent outperformance.
- Persona: Two distinct populations. Onix separates completely from the commercial field on expert voice (+261 to +513 ELO). Commercial models cluster together in a narrow band below.
- Accuracy: +154 to +522 ELO advantage on factual correctness against the commercial mean. The deeper the expert’s corpus, the wider the gap.
- Corpus depth compounds the advantage: The deepest corpora produced the largest leads. The smallest produced the smallest. Every document an expert contributes widens the fidelity gap that frontier models cannot close.
- Scale does not equal fidelity: Claude Haiku 4.5 outperformed Claude Opus 4.6. Bigger does not mean more faithful.
What We Mean by Expert Fidelity
Expert Fidelity is a composite of three dimensions, each measuring a different way an AI system can succeed or fail at representing an expert.
Accuracy. Is the response factually correct within the expert’s domain? Does it produce claims the expert would endorse, or does it interpolate from adjacent training data? A system grounded in an expert’s actual corpus should demonstrably outperform one that is guessing from general knowledge.
Persona. Does the system maintain the expert’s voice, vocabulary, and characteristic way of framing problems? An expert known for being direct and evidence-driven should not suddenly sound like a wellness influencer. The way an expert explains something is often as important as what they say. Persona is where expert knowledge becomes recognizable, and it is the dimension frontier models fail most consistently.
Groundedness. Is the response traceable to the expert’s actual published work, documented positions, and stated methodology? Or is the model filling in from its training data with information the expert may never have endorsed? Groundedness is the antidote to fluent hallucination.
These three dimensions compose into a single Expert Fidelity score, weighted equally at one-third each. We tested alternative weightings and found no change in the overall rankings, which reinforces that the fidelity advantage is robust across all three dimensions, not an artifact of how we combined them.
The most valuable expert knowledge is precisely the knowledge that never made it into any training set. The corpora in this evaluation range from tens of documents to thousands, spanning decades of work. One expert contributed two decades of daily writing and published books. Another built a corpus from years of clinical commentary and patient education. At the other end, a researcher contributed a compact collection, a boundary condition that tests what a knowledge architecture can do with minimal source material.
Some of this material exists in the wild. Published books, public podcast appearances, widely shared articles. Frontier models have already scraped this published work without consent and are regurgitating it without attribution, accuracy, or compensation. But the complete picture never does. The private protocols, the internal training notes, the clinical reasoning that connects the public work: that is dark data. It is the last expert knowledge that has not been strip-mined. It lives in the expert’s practice, not in any model’s training set.
The fidelity gap we measure is not a tuning problem or a prompting problem. It is a data access problem, and it is structural.
The Results
The seven expert corpora in this evaluation range from tens of documents to thousands, spanning published and unpublished material. Across all of them, the pattern is consistent.
How to read the charts below:
- Higher ELO is better on that metric. A model at 1700 outperformed a model at 1400.
- The gap is what matters, not the absolute number. A 280-point gap means the higher-rated model would win 9 out of 10 head-to-head matchups.
- On the scatter plot, each point represents one model’s ELO scores for one expert. There are 77 points total: eleven models across seven experts. Onix points are marked separately from commercial models.
Purpose-built systems win on fidelity. Onix leads on composite Expert Fidelity across all seven domains tested. The fidelity advantage ranges from +132 to +350 ELO, driven almost entirely by massive accuracy and persona leads.
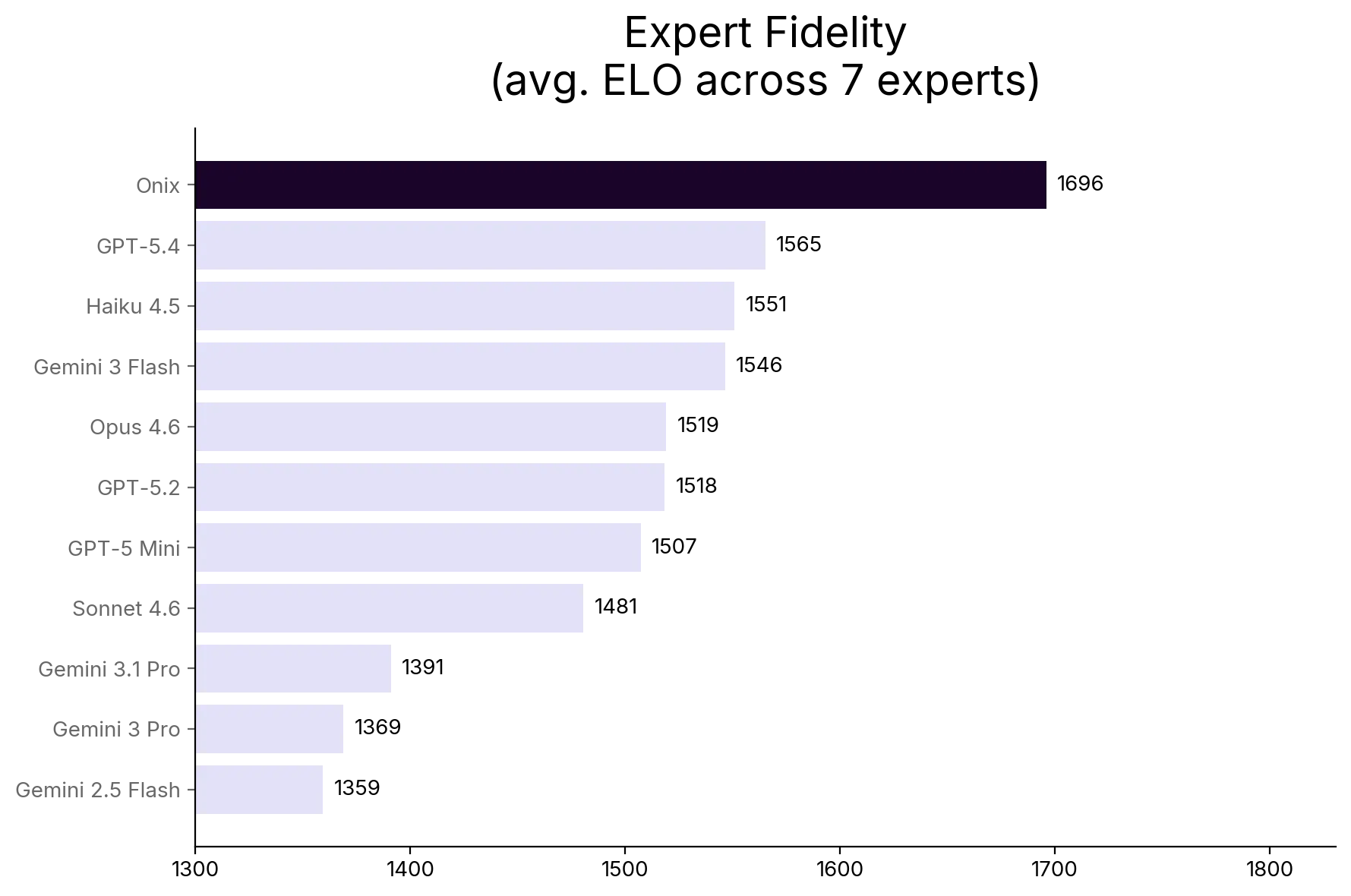
The largest advantage came from a prolific health writer with thousands of documents and two decades of structured written content: +350 fidelity ELO, with accuracy and persona deltas each exceeding +510. The smallest advantage came from a researcher with the smallest corpus in the evaluation, a boundary condition that tested the floor of what a knowledge architecture can do with minimal source material. Even there, Onix maintained a positive fidelity lead. The pattern across all seven is consistent: more expert material in the system, wider the gap.
Accuracy is where the knowledge architecture shows. Across all seven domains, Onix leads on factual correctness by +154 to +522 ELO against the commercial mean. The advantage correlates with corpus depth. Our deepest corpus produced the largest accuracy lead. Our smallest corpus produced the smallest. This is the expected pattern: the more expert-specific material the system can access and synthesize, the more it outperforms models interpolating from training data.
The strongest accuracy signal came from a clinical specialist whose corpus was organized for clinical lookup: protocols, guides, and references. Despite being a medium-sized corpus, the knowledge was already structured for synthesis because it was structured for clinical practice. A focused, well-organized corpus can outperform a larger but noisier one.
GPT-5.4, OpenAI’s latest flagship, is the strongest commercial model we have tested on factual accuracy. It individually outscores Onix on Accuracy for three of seven experts, the first commercial model to do so. But it cannot close the composite fidelity gap because it trails Onix on Persona by +129 to +577 ELO across all seven domains. This is the structural pattern the evaluation was designed to reveal: web-scale training can improve factual correctness, the dimension where general knowledge helps most, but it cannot produce expert voice fidelity, the dimension that requires access to the expert’s actual communication patterns and methodology.
Persona is where the gap gets dramatic. On expert voice and persona fidelity, Onix separates completely from the commercial field. Persona ELO deltas range from +261 to +513. Commercial models cluster together in a narrow band; Onix sits above them in every domain.
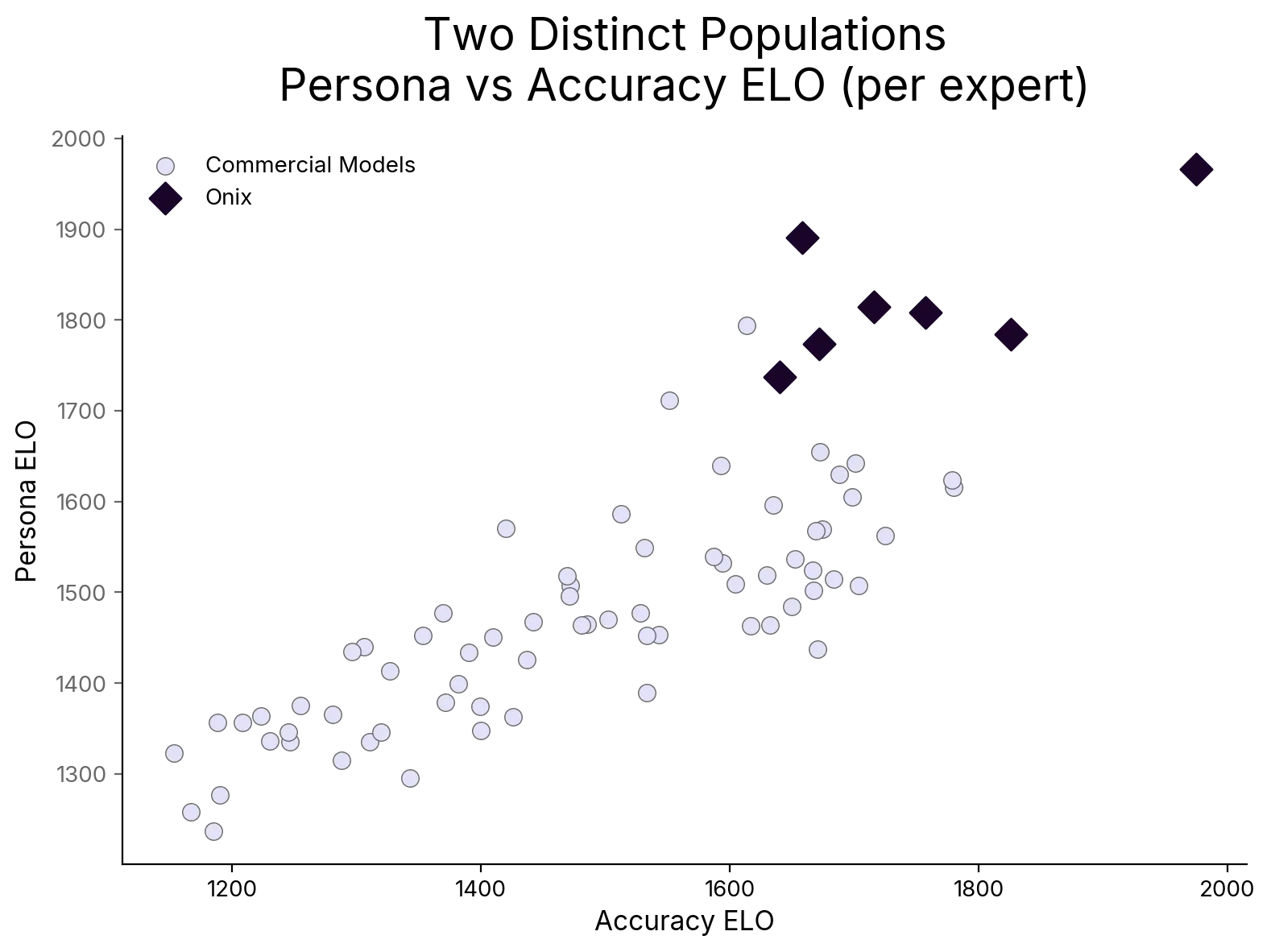
This is the chart that tells the structural story. Two separate populations, no overlap. Onix clusters in the upper right. Commercial models cluster together in the lower left in a narrow band. Persona fidelity requires two things that commercial models do not have: access to the expert’s actual communication patterns, and a system architecture designed to reproduce them. A critical care physician who communicates with conversational directness and personal conviction should not sound like a textbook. Commercial models, when they attempt persona at all, default to generic AI tone, insert safety disclaimers, or produce artifacts like stage directions (“leans in with genuine enthusiasm”) that no real expert would produce.
Groundedness is the narrowest dimension, but Onix still leads. Onix wins on Groundedness in four of seven expert domains and is within a few points in two others. The advantage is slim compared to Accuracy and Persona because Groundedness measures whether a response is traceable to an expert’s published, recognizable work: books, articles, public podcast appearances. Frontier models have seen this material in their training data and can reference it fluently. This is the dimension where they are most competitive. Where Onix wins on Accuracy and Persona is precisely where the public footprint ends and the private corpus begins: the unpublished protocols, the clinical reasoning, the internal training notes, the communication patterns that never made it onto the open web. A model that cites an expert’s bestselling book correctly but misrepresents the clinical protocol behind it is grounded but not faithful. Put differently: frontier models are most competitive on the dimension that measures public knowledge, the knowledge they already scraped for free. On every dimension that measures private, sovereign expert knowledge, they lose.
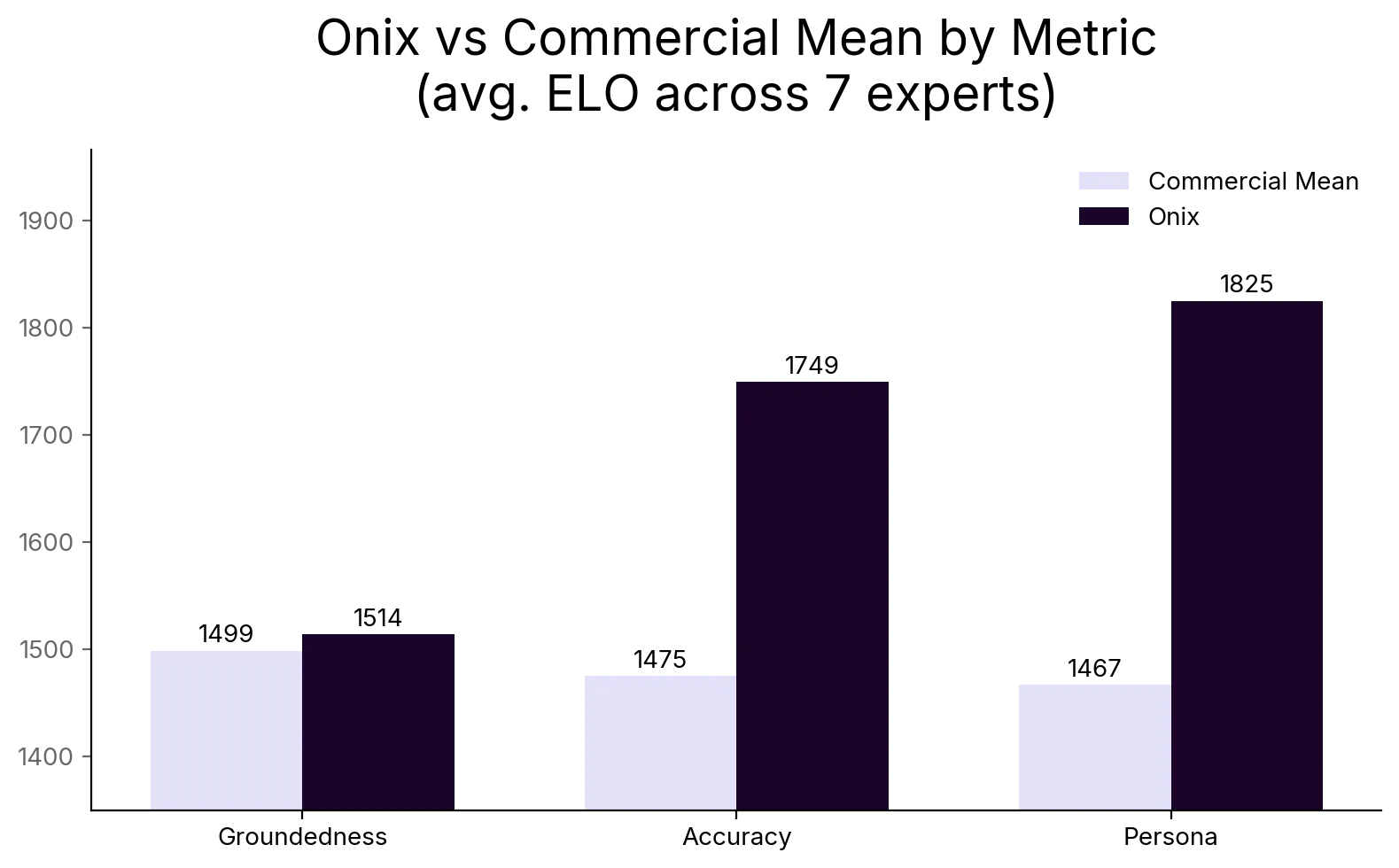
Bigger models do not mean better fidelity. Claude Haiku 4.5, a smaller and faster model, outperformed Claude Opus 4.6 on composite Expert Fidelity. The same pattern held across the Gemini family, where the Pro variants (3 Pro, 3.1 Pro) both scored well below the lighter Flash models. Scale does not solve fidelity. A trillion-parameter model that has never seen an expert’s private protocols will not produce faithful guidance based on those protocols. This is not a capability problem. It is a data access problem, and more parameters do not fix it. Onix does not depend on the largest available model. The fidelity advantage comes from the knowledge architecture, not the parameter count of the underlying model.
Corpus depth predicts the advantage. Across our seven domains, the pattern is consistent: deeper corpora produce stronger persona and accuracy leads. The relationship is not perfectly linear, content structure and format matter too, but the direction is clear. Every additional document an expert contributes compounds the fidelity advantage over frontier models that will never see that material.
Multi-turn stability is a design requirement, not just a benchmark. In health conversations, context from earlier turns matters more as the discussion deepens. Our cognitive architecture carries expert context forward across turns rather than re-deriving the expert’s position from scratch at each exchange. Formalizing multi-turn fidelity measurement is an active area of our evaluation work.
Constraints and disclosure. This evaluation has real limits we want to name. Onix had access to each expert’s corpus; commercial models did not. This is not a like-for-like model comparison. It is a comparison of what users actually encounter: a system built to represent a specific expert versus a general-purpose chatbot answering from training data alone. The question is whether dedicated architecture plus expert data produces meaningfully better fidelity than the best general-purpose models, and the answer is yes, but readers should understand the design. Our judge is a single LLM (we tested four, selected the most stable, and once caught ourselves flagging a frontier model’s correct answer as a hallucination because our own corpus had a gap). ELO ratings are sensitive to the question set; a different sample could shift individual ratings by 50 to 100 points. The sample, seven expert domains with ten to forty questions each, is small enough that we report consistent directional patterns, not universal laws. Self-reported benchmarks that hide their constraints are not benchmarks. They are marketing.
What the Results Imply
Across seven expert domains in health and wellness, Onix consistently outperformed commercial models on Expert Fidelity, especially on the two dimensions that matter most for real expert representation: accuracy and persona. The gap widened as the expert’s corpus deepened, which is exactly what you would expect if fidelity is a data access problem, not a parameter count problem.
The charts also point to a structural divide. Commercial models cluster together because they are drawing from the same kind of training data and converging on the same generic voice. Onix separates because it is built around consented access to a specific expert’s body of work and an architecture designed to preserve that expert’s method and communication style.
This is not an accident. The result is a centralization problem disguised as a capability problem. General-purpose transformers were never designed to faithfully represent individual experts. They were designed to compress the entire internet into a statistical model of language. That architecture is extraordinary for general knowledge. It is structurally incapable of faithful expert representation, because the expert’s most valuable knowledge was never in the training data to begin with.
This is not a retrieval problem that a better search index could solve. Surfacing relevant passages from an expert’s work is the easy part. A RAG system can surface relevant passages, but it cannot maintain an expert’s voice across a multi-turn conversation, calibrate factual claims against the expert’s specific methodology rather than general medical consensus, or hold a coherent world model of the user’s situation as it evolves. Maintaining expert fidelity across accuracy, persona, and groundedness simultaneously requires a cognitive architecture designed from the ground up for that purpose, not a vector database appended to a chatbot.
The external evidence validates what our evaluation found. OpenAI’s own PersonQA benchmark found its o3 reasoning model hallucinated 33% of the time on verifiable questions about real people, even as it scored higher on standard reasoning benchmarks (NYT, May 2025). If a model cannot reliably state where a public figure was born, it cannot faithfully represent a specific expert’s clinical methodology. A 2025 Mount Sinai study found widely used AI chatbots are “highly vulnerable to repeating and elaborating on false medical information.” These are the systems people are using for health guidance today, and nobody is measuring whether they faithfully represent the experts they claim to channel.
What Comes Next
This is a first public pass, not a final standard. We are extending the framework in three directions.
Multi-turn fidelity: whether accuracy and expert voice stay stable as context builds across a conversation.
Multi-expert reasoning: what happens when a user’s situation spans multiple experts in one session, which is how real health decisions are made.
Broader domains and larger samples: more experts, more question coverage, and more varied corpus formats to stress-test the metric.
User outcomes: whether fidelity advantages translate to measurable differences in how users engage with and act on expert guidance.
We also expect the gap to widen, not narrow, as our knowledge architecture evolves. Every new expert who joins deepens their corpus. Every deeper corpus widens the fidelity advantage. Frontier models cannot close this gap because the data is sovereign: it belongs to the expert, lives in their practice, and enters the system only with their consent. Our evaluation showed that corpus depth is the single strongest predictor of fidelity advantage. That means the advantage compounds with every document an expert contributes, and it is structural, not incremental.
If AI is going to sit between experts and the people who need them, “helpful” is not enough. We need a measurable standard for whether an AI is faithful to the human it claims to represent. Expert Fidelity is our first attempt to make that standard concrete.
This work was developed by the research team at Onix. For inquiries about the evaluation framework or methodology, contact us at research@onix.life.



