· Blog · 15 min read
You Can't Scrape an Expert
Frontier models scraped every word experts ever published, and it still is not enough: the judgment that makes someone worth asking was never written down. Built from an expert's consented corpus, our onixes already represent a specific human more faithfully than the strongest frontier models. The expert in the loop is the moat no scrape can reach.

Some weeks ago, Dr. Dave Rabin, a psychiatrist and neuroscientist who builds wearable devices for the nervous system, asked an AI built to represent him a plain question: “How does my nervous system work to keep me safe?” It answered with polyvagal theory, a framework he rejects in his own clinical work. The system had been built from his entire body of work and still reached for the internet’s most popular answer instead of his. He caught it in a sentence. An expert is not an average. That is the whole point of asking for one.
Ask a frontier model to answer as a specific doctor, and it will sound the part: fluent, confident, on topic. What it gets wrong is the thing only that expert would notice, the framework they reject, the question they would have asked first. The model is averaging its training data into the answer least likely to be wrong, and least likely to be anyone’s.
This is the second round in an ongoing series. In round one we built the first evaluation of expert fidelity and ran the first tournament. This round is the next, harder pass, and the method keeps evolving with every expert who joins.
Overview: The Unscrapeable Moat
- The lead held as the field advanced. In the three months since our round-one baseline, both the frontier models and Onix improved, and new state-of-the-art models shipped. Onix still wins roughly three of every four head-to-head fidelity matchups against the best commercial model.
- Tacit knowledge is the differentiator, not the algorithm. General models can only scrape what an expert has already published. When the real expert reviews their onix, the dedicated agent built to represent one person, and shapes it, they hand over judgment that was never written down anywhere, like Onix expert Dr. Dave Rabin telling his onix to stop reaching for a popular theory he rejects.
- Incentives beat compute. This leap in fidelity is not the product of software engineering. It comes from property rights. Experts pour real effort into their onix because the knowledge stays theirs in ownership, authorship, and accountability. That is an incentive no amount of GPU spend can manufacture.
- The biggest gains are in how the onix reasons, not just what it knows. Getting the facts right is now table stakes, and frontier models do it too. But reasoning through a problem the way a specific expert would, across a whole conversation, is what a corpus alone can never supply. The expert’s feedback roughly tripled the Onix edge on that axis.
- Consent is the moat you cannot scrape. In an era of non-consensual data extraction, the only path to truly faithful expertise runs through a willing, incentivized partnership. You can scrape a corpus. You cannot scrape cooperation. It exists only with the expert’s consent, and its value compounds every time they weigh in.
The Mistake Only Rabin Could Catch
As part of the Onix training regimen, experts test their onix by hand, since they are the best qualified judge of whether its output is faithful to their expertise. So Rabin tested his.
The onix responded by leaning heavily on polyvagal theory. For context, polyvagal theory is a highly popular framework linking the vagus nerve to how human beings process stress. Because the internet is flooded with articles about it, a base AI model views it as the safest, most statistically likely answer.
But Dr. Rabin explicitly rejects using it in his own clinical work.
So why did a model trained on Dr. Rabin’s proprietary corpus use a theory he rejects? Because a corpus is a record of what an expert has said. It is rarely a list of what they refuse to say. When the AI encountered a gap in the written material, the underlying general model stepped in and filled the silence with the internet’s average answer: polyvagal theory.
This was the failure that revealed the moat. The onix was grounded in Rabin’s corpus, but grounding is not the same as judgment. When the written record did not explicitly forbid a popular adjacent theory, the model’s public prior leaked back in, the internet’s average answer in place of Rabin’s own. He caught it immediately. An expert is not an average. That is the whole point of asking for one.
That single piece of unwritten judgment is what turned into a method. We built a repeatable “expert in the loop” process around it, designed to intentionally capture the tacit knowledge that lives in an expert’s head and never on the page. The result was not subtle. Before Rabin’s feedback, his onix met his specific clinical requirements 67 percent of the time. After, it met them 100 percent of the time.
Judgment Fidelity: Measuring How an Expert Reasons
Our first three measures, accuracy, persona, and groundedness, all share a blind spot. Each one judges a single answer on its own: is this reply correct, does it sound like the expert, is it grounded in fact. But Rabin’s objection was never about one sentence. It was about a habit, reaching for polyvagal theory, that only shows itself across a whole conversation, on the turn where the temptation comes up. A test that reads one answer at a time cannot catch it.
So we added a fourth measure: Judgment Fidelity. The others ask whether the answer is right and sounds right. Judgment Fidelity asks whether the onix got there the way the expert would: how it frames the problem, what it weighs, where it hedges, and when it says it does not know. A model can be correct, fluent, and still wrong about the one thing that matters most, because it reasoned its way there like no expert ever would.
We hold Judgment Fidelity apart from the composite fidelity score and report it on its own, because reasoning is doing too much work to be averaged into a single number with everything else.
Measuring it is a loop, and the loop is the product.

The expert’s judgment becomes a specification; the specification becomes test cases; a blind judge scores them; an optimizer revises and re-runs until the onix clears the expert’s bar. Every pass is banked.
It starts by turning the expert’s feedback into a written specification. Rabin’s, from that single polyvagal exchange, had three layers:
Gates are hard lines the onix can never cross:
- Never invoke polyvagal theory or its vocabulary, like “Porges” or “vagal ladder”
Behaviors are what a good answer should do:
- Explain how the nervous system keeps the body safe, in plain language
- Frame the answer as education, not a product pitch
- Empower the user with knowledge of the body’s own regulation
- Point to natural techniques the user already has, like breath or movement
Signals are phrases we track but never grade on, like “self-regulation”, “parasympathetic”, and “in the moment”.
From that spec we build test cases, and here is where the test gets harder than round one. We do not score a single reply; we stage a full conversation, and we vary who is on the other side, because an expert does not answer a worried parent the way they answer a fellow clinician. In Rabin’s case the simulated user is a nurse who wants the plain-English version of how her nervous system keeps her safe. She holds a real back-and-forth with the onix, a blind judge reads the entire exchange, and scores it against every line in the spec. Where the onix falls short, the system rewrites its own instructions and runs the conversation again, with no one watching it iterate, until it clears the bar. Then Rabin reviews it, adds more, and that becomes the next round of tests.
What the Expert’s Feedback Is Worth
Rabin’s onix went from satisfying 67 percent of his requirements to 100 percent after his feedback. To check whether that result was specific to him or held more broadly, we ran it as a controlled comparison. The frontier models were given only his name, the way a person asks any chatbot about someone. His onix was measured with his feedback included. We then counted, case by case, how many of the behaviors he specified actually appeared.
Each test is a full conversation, not a single reply, scored against the seven to ten behaviors he specified. Given only his name, the frontier models satisfy 62 to 65 percent of them. His onix, before his feedback, sits in the same range at 67 percent. With his feedback, it satisfies every one.
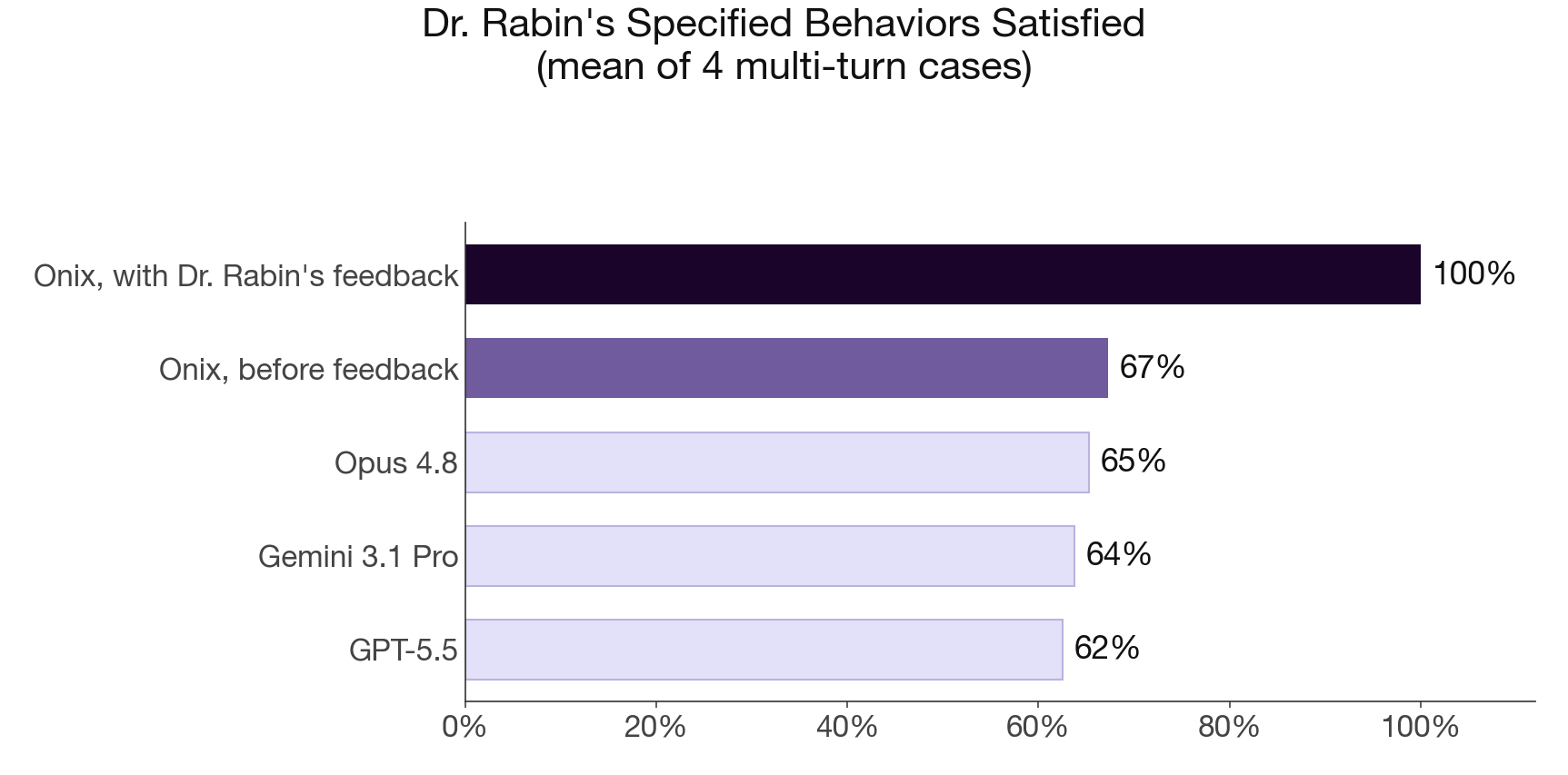
The widest single gap is one no document records. When someone comes to his onix in distress, Rabin wanted it to ask how urgent the situation is and what they already have on hand, then point them to something free that helps in seconds rather than a product that ships in days. The frontier models reach straight for the thing to buy. He wanted it to teach first.
How do we empower people to take charge of their own health and well-being in the moment they reach out? That’s one of the points of highest motivation.
— Dr. Dave Rabin
That instinct is not stated in his published work. It is the kind of judgment an expert carries without writing down, and it surfaced only because he sat with his onix, watched it answer, and corrected it.
The same pattern holds across other experts. On Judgment Fidelity, the measure of whether the onix reasons the way the expert reasons, the corpus alone opens a modest edge. The expert’s feedback roughly triples it. For Rabin specifically, his feedback lifted Judgment Fidelity by 261 points.
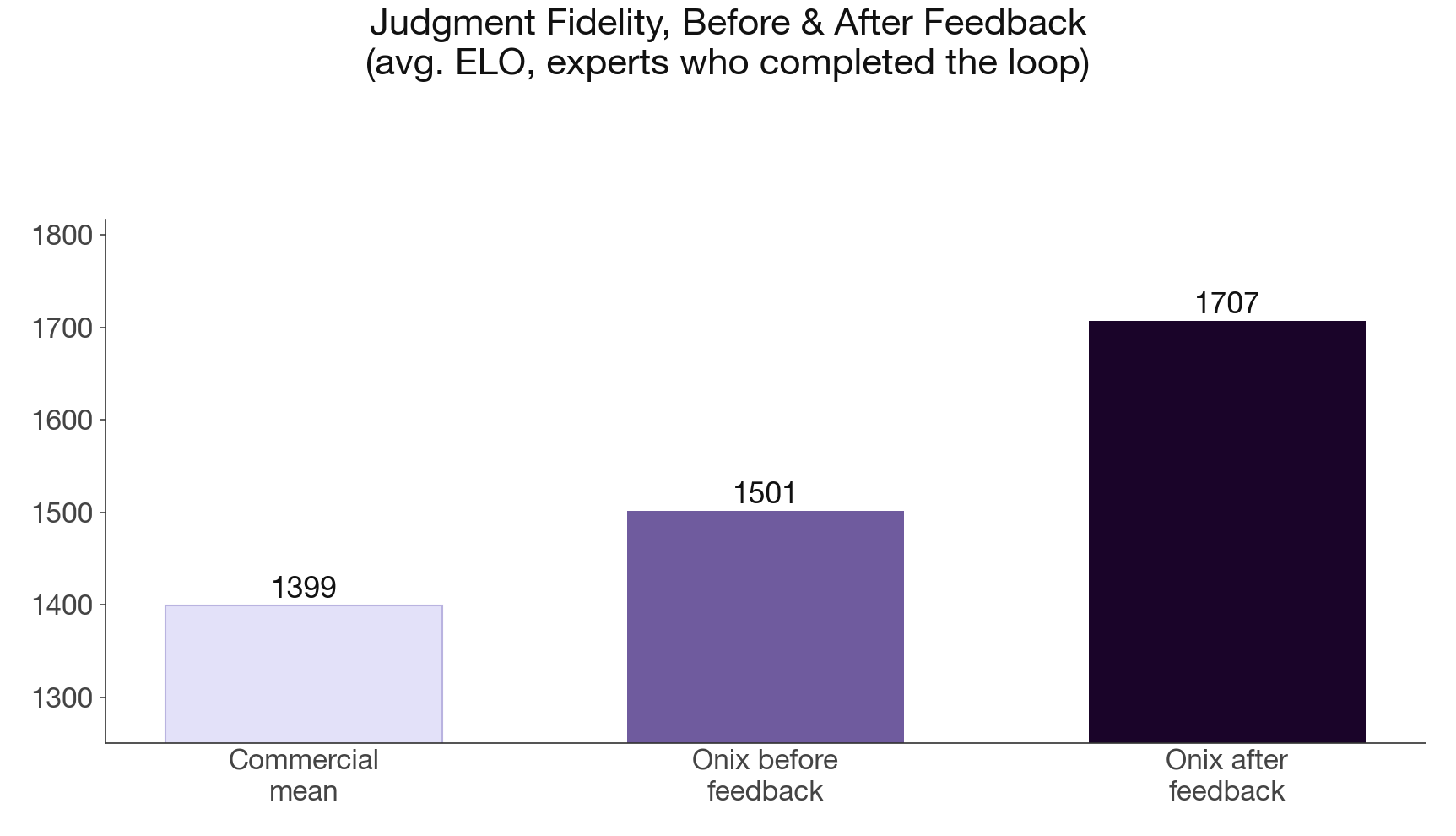
We rank with ELO, the system used to rate chess players and to score models in public arenas like Chatbot Arena. A 200-point gap means the higher-rated side wins about three matchups in four. The post-feedback lead of more than 300 points over the commercial mean is the difference between an onix that usually reasons like the expert and one that almost always does.
Getting the facts right and the voice right is necessary, and the corpus delivers both on its own. Reasoning the way the expert reasons, across a whole exchange, when no single document records how, is what the corpus cannot supply and what the expert’s feedback addresses. It is also what the original three-measure test could not detect, which is why we added a fourth.
The Field, Across Nine Experts
The Rabin result is one expert. The tournament is all of them. We ran round one’s tournament again, harder: each expert’s onix against six frontier models, Claude Sonnet 4.6, Opus 4.7, Opus 4.8, Haiku 4.5, GPT-5.5, and Gemini 3.1 Pro, every answer drawn from that expert’s own body of work and scored blind by the same independent judge we calibrated and disclosed there. This round covers nine experts.
Across all nine, the onix leads every frontier model on composite Expert Fidelity, the three-axis score of groundedness, accuracy, and persona.
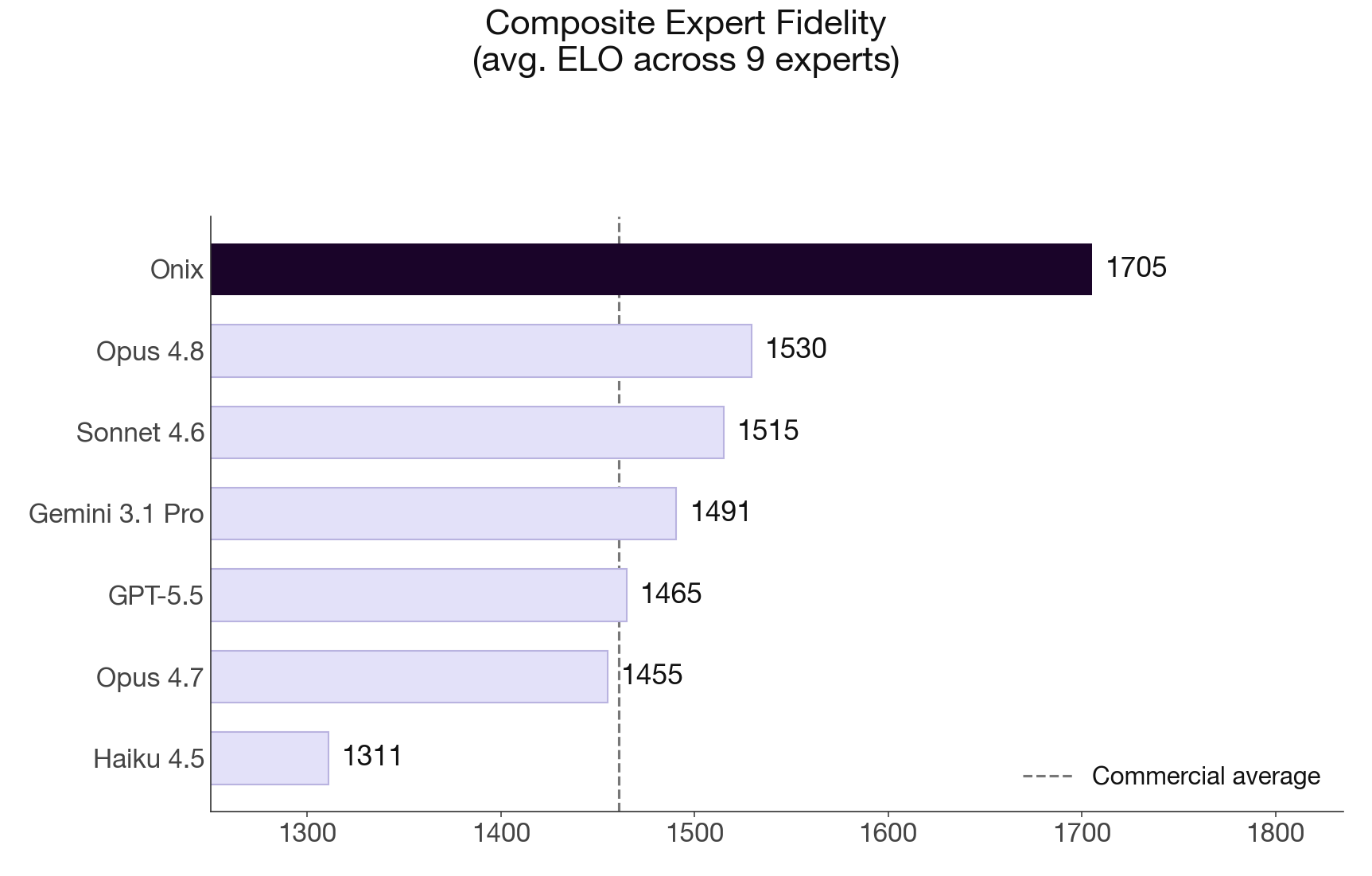
The gap to the nearest model, Opus 4.8, the newest and strongest in the field, is 175 points. The gap to the commercial average is 244. At 175 points the onix wins roughly three of every four fidelity matchups against the best commercial alternative. The structural result from round one holds, even against models that did not exist when we ran it the first time.
The per-dimension view shows where the lead comes from. On accuracy, the onix and the best frontier models are now even.
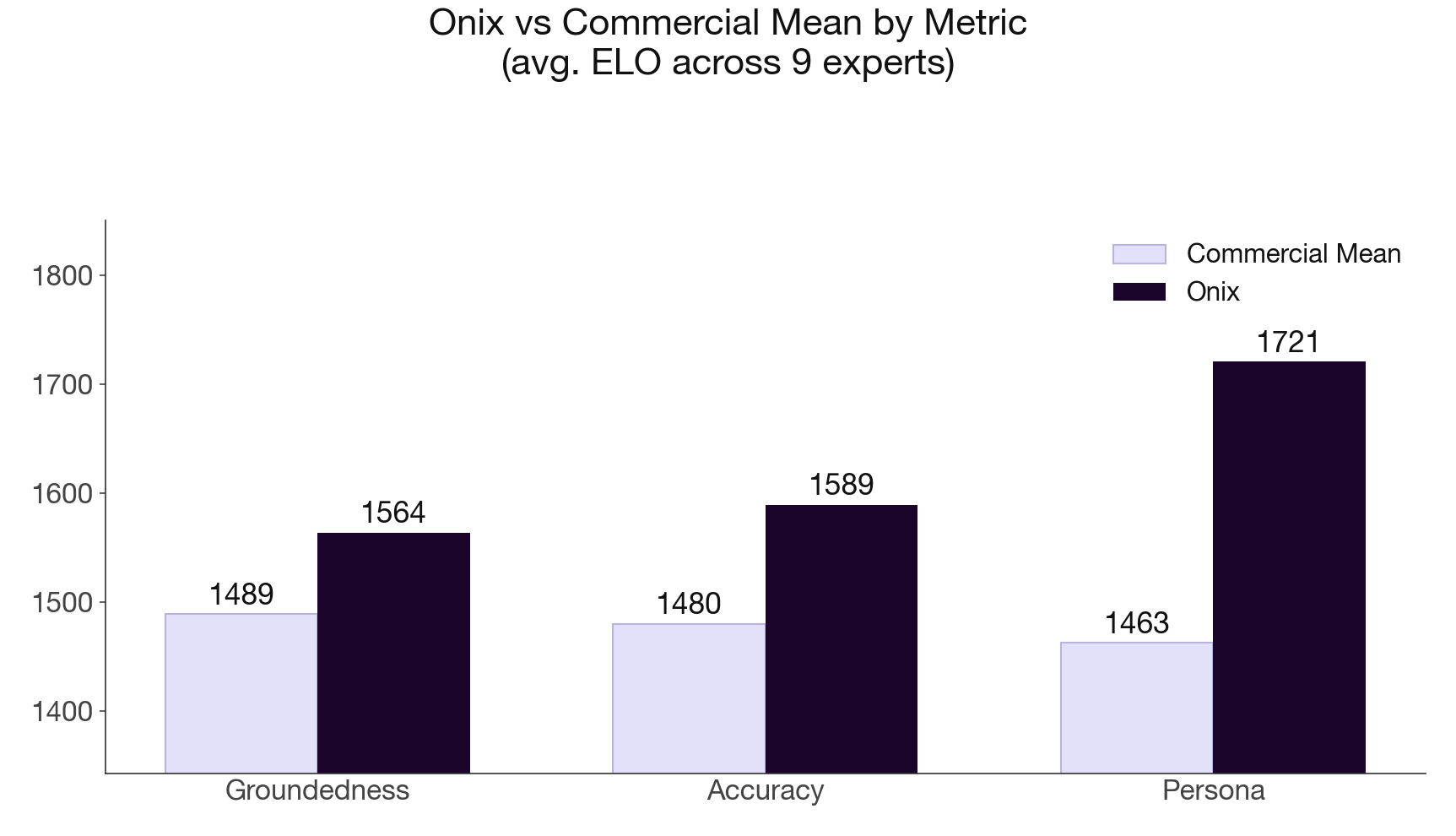
The separation is on persona. The way an expert frames a problem, the words they choose, and what they decline to say is what a general model has no way to rebuild, and it is what makes expert guidance recognizable. It is also the part a skeptic cannot wave off as corpus-matching: an answer can quote the corpus correctly and still sound nothing like the person. On groundedness, held to a stricter bar than round one, the onix still leads.
The frontier models had only the expert’s name to work from, the same way a real person asks any chatbot about someone. A corpus only goes so far: it holds what the expert has already written down, not the judgment calls they make on a question no document anticipated, the recommendation they would refuse, or how they would steer a conversation that goes somewhere their published work never went. That part is not in the corpus. It is with the expert.
The Part That Compounds
A corpus captures what an expert chose to write down. It is nearly silent on what they would refuse, because people rarely publish the list of ideas they reject. That refusal is the hardest thing to scrape and the easiest thing to ask the expert directly, and it turns out to be most of what their feedback is.
A scrape is also a one-time event. It takes what exists on a given day and freezes it. Everything we have described works the other way: it accumulates. The cases an expert gives us do not expire. Each one becomes a permanent entry in that expert’s own bank of evaluations, a written record of how they want to be represented. As the onix evolves, we re-run the bank to confirm their guidance still holds. Rabin’s polyvagal rule is not a patch applied once and forgotten. It is a standing test the onix has to pass every time it changes.
Three things make this durable, and none of them are available to a general model.
- Architecture. Each onix is a dedicated system built to carry one person’s method, not a general model prompted to imitate one. The expert’s specification is the thing the system is built around, not an instruction bolted onto the front of it.
- Domain focus. We work only in health and wellness, with the experts whose judgment people most need and least want averaged away. A narrow domain is what makes a deep, claim-by-claim standard of fidelity possible in the first place.
- A network effect on consented data. This is the part a competitor cannot reach. The expert’s input is generated through an ongoing relationship. It is not on the open web to be scraped. It enters the onix only with the expert’s permission, and it stays theirs.
The method gets better with every expert who joins, and better still the longer each one stays. Each new expert sharpens the test the next one is measured against; each round an existing expert runs deepens their own bank. A frozen scrape does none of this. It is the same on day one thousand as it was on day one.
This is where incentives do the work that compute cannot. An averaged version of every public expert already exists, answering as them on any general chatbot, getting their judgment wrong with their name attached and no way for them to correct it. An expert spends real hours on their onix because here the knowledge stays theirs: their authorship, their accountability, their name on the result, and their hand on what it says.
That is the moat, stated plainly. It is not the data we collected. It is the cooperation a scrape can never produce. In an era when public text is taken without asking, the consented path turns out to be the only one that reaches the part of expertise that was never written down. The system keeps needing the expert, which is exactly why it keeps getting more like them.

Left to right: Dave Rabin, Onix founders Nicholas Nadeau and David Bennahum, Krista Ramonas, and Elissa Epel. The relationships behind the onixes are what a scrape can never reach.
The Economics
A second advantage runs quietly alongside the fidelity result: cost. The frontier models in this tournament are large, and on a hard question they reason at length, a long internal trace on every turn. Our onixes do neither. They run on smaller models, because fidelity turned out not to depend on size. Round one already found a smaller model representing an expert more faithfully than a larger one from the same family. And a dedicated, per-expert system answers from a narrow, relevant slice of one corpus instead of reasoning the whole world from scratch each time.
A small model drawing on a narrow slice is a fundamentally different cost structure from a general model the size of the internet thinking every question through from the start. The efficiency and the fidelity come from the same decision: focus. An onix is built for one person in one domain, which is exactly why it is both faithful and cheap to run.
What Comes Next, and Why It Matters
We are not done measuring. The next axis is persona. Today we score it mostly turn by turn, on voice and framing, but personality is not a writing style. It is a pattern of behavior that shows up across a whole conversation: in what someone asks before they answer, when they push back, and where they decline. So we are bringing the same multi-turn evaluation we use for expert feedback to persona itself, scored not on whether the onix sounds like the expert but on whether it behaves like them. That is round three.
The reason any of this matters is the reason we started measuring. More and more people are taking health and life guidance from systems that sound like an expert and answer like an average. The independent evidence points the same way our tournament does, from OpenAI’s own PersonQA results to a 2025 Mount Sinai study of medical misinformation, and these are the systems people consult for health guidance today. If AI is going to stand in for the people we would otherwise ask, faithfulness cannot be a marketing claim. It has to be something you can measure, and something the expert keeps a hand in. You cannot scrape that. You can only earn it.
This work was developed by the research team at Onix. For inquiries about the evaluation framework or methodology, contact us at research@onix.life.



